데이터 로드 중 인코딩 관련 에러
공공데이터를 불러오는 과정에서 아래와 같은 오류가 발생했다.
ParserEroor: Error tokenlzing data. C error: Expected 14 fields in line 1273, saw 15

구글링을 해 보니 몇번째 열, 행 에서 오류가 발생한 듯 했다.
데이터가 그리 크지 않아 직접 실행하여 눈으로 확인해봐야겠다.
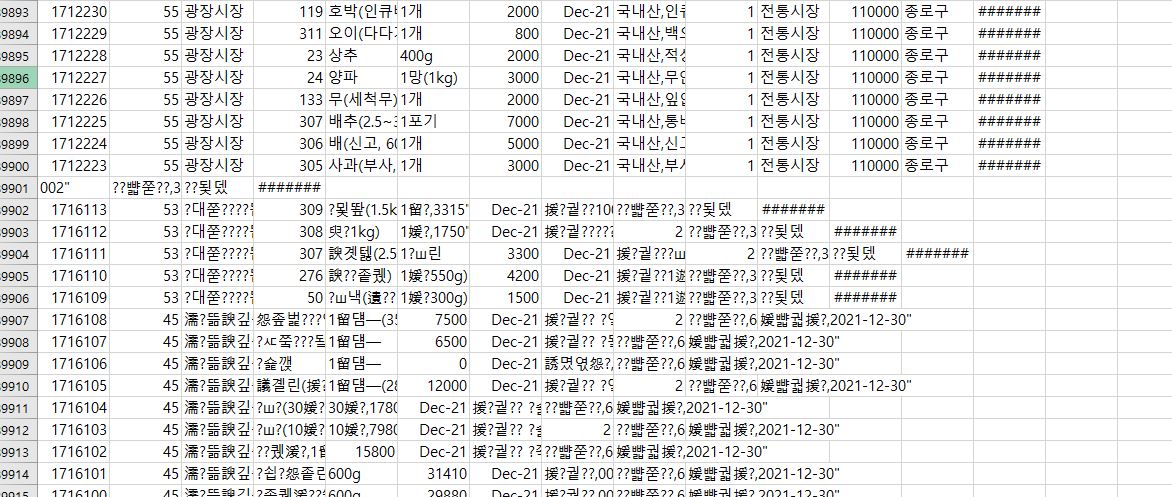
한글이 깨져서 오류가 발생한듯 했다.
한글이 깨졌을 경우 파일을 유니코드(UTF-8) 로 다시 저장하여 인코딩을 해 주면 된다고 한다.
위의 과정은
Excel(엑셀) csv파일 한글화, 텍스트나누기, 필터, 엑셀한글깨짐 해결
IT전문 블로그 (rbamtori, 최지훈)
blog.naver.com
를 참고 했다.
파일을 재 인코딩 한 후에 다시 read_csv 를 통해 파일을 불러오니
UnicodeDecodeError: 'cp949' codec can't decode byte 0x80 in position 99392: illegal multibyte sequence

이번엔 이런게 뜬다
아 cp949 가 아니라 utf-8 로 인코딩 했으니 저것도 바꿔줘야되나? 싶었다
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc0 in position 1: invalid start byte
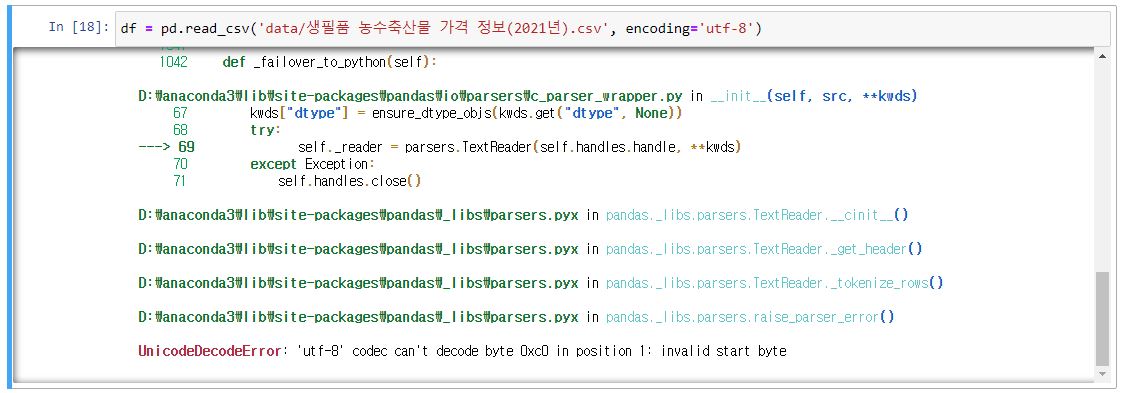
아니었다.
이 과정을 몇시간 동안 반복했다.
결국 맨 처음으로 다시 돌아갔다.

마침 강의에서 사용되는 데이터가 1월~6월 의 데이터였는데,
업데이트가 되어 21년 전체의 정보가 담겨있던 데이터라
깔끔하게 한글이 깨지는 부분을 지워버렸다 ^^ (정신건강에 해로울뻔했다)
(데이터의 양이 많아 일일이 드래그를 하기엔 7개월 정도 걸릴것같아서 단축키를 사용했다)
// 지우고싶은 시작부분에 커서를 놓고 Shift + Ctrl + End 키를 눌러 한번에 드래그 //
다시 판다스로 돌아와 파일을 불러왔다
(cvs 파일 이름이 다른 이유는 위 과정을 거친 후 이기때문)

뭔 이상한 처음보는 오류가 나왔다
이것저것 하느라 시간이 오래지나 다시 처음부터 해야됬다.
자칭 기본세팅이라 불리는 명령어를 실행해줬다.
정상적으로 파일도 불러와지고 df 를 통해 담긴 데이터를 확인했다
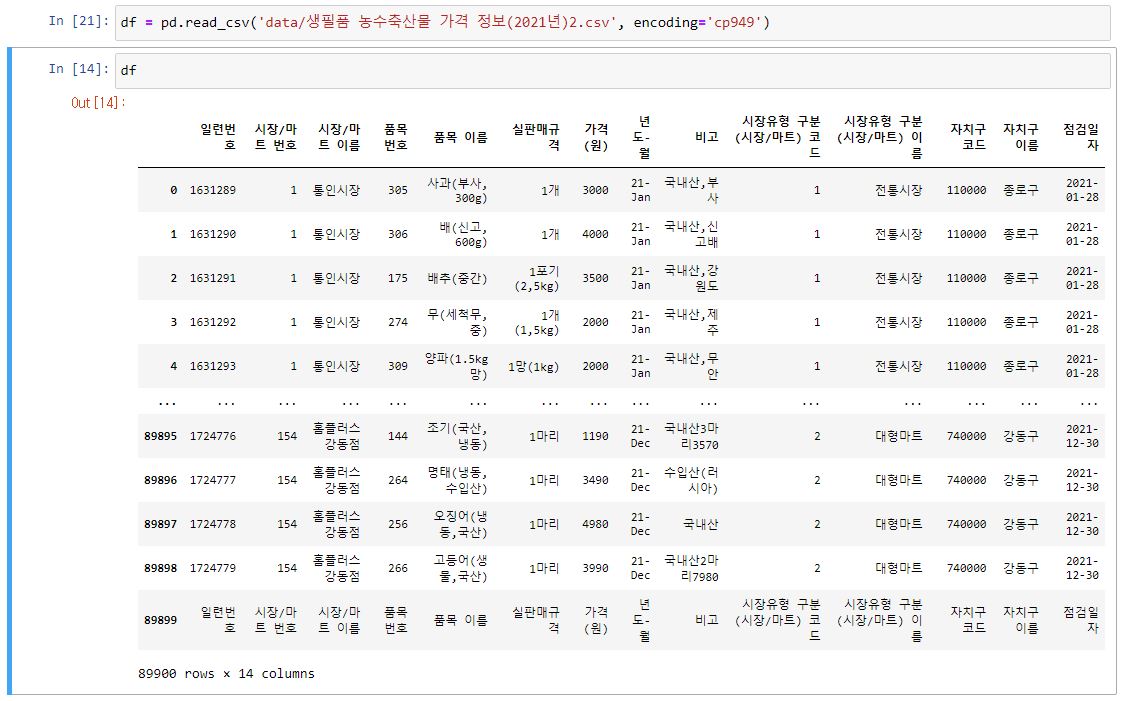
휴우 편----안
실습을 마저 진행하러 간다